作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/6c5064b1a9544809/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
摘要: 本文意在理清知识库增强型语言模型。若有错误,请大家指正。
关键词:KBALM,知识库,检索增强生成
一、一个简单介绍
最近微软的KBALM方法(KNOWLEDGE BASE AUGMENTED LANGUAGE MODEL)[^1]让人眼前一亮,知识库增强型语言模型(KBALM)大有成为下一代上下文技术的潜力。这篇论文提出了一种增强预训练模型LLMs的外部知识的新框:基于知识库的语言模型(KBLAM)。具体而言就是通过现有的工具将外部语料库转换为结构化的知识库(KB),它总结了数据中的关
键信息并生成包含实体名称($
这里需要注意KBALM只探索人将{实体名称($
二、核心原理
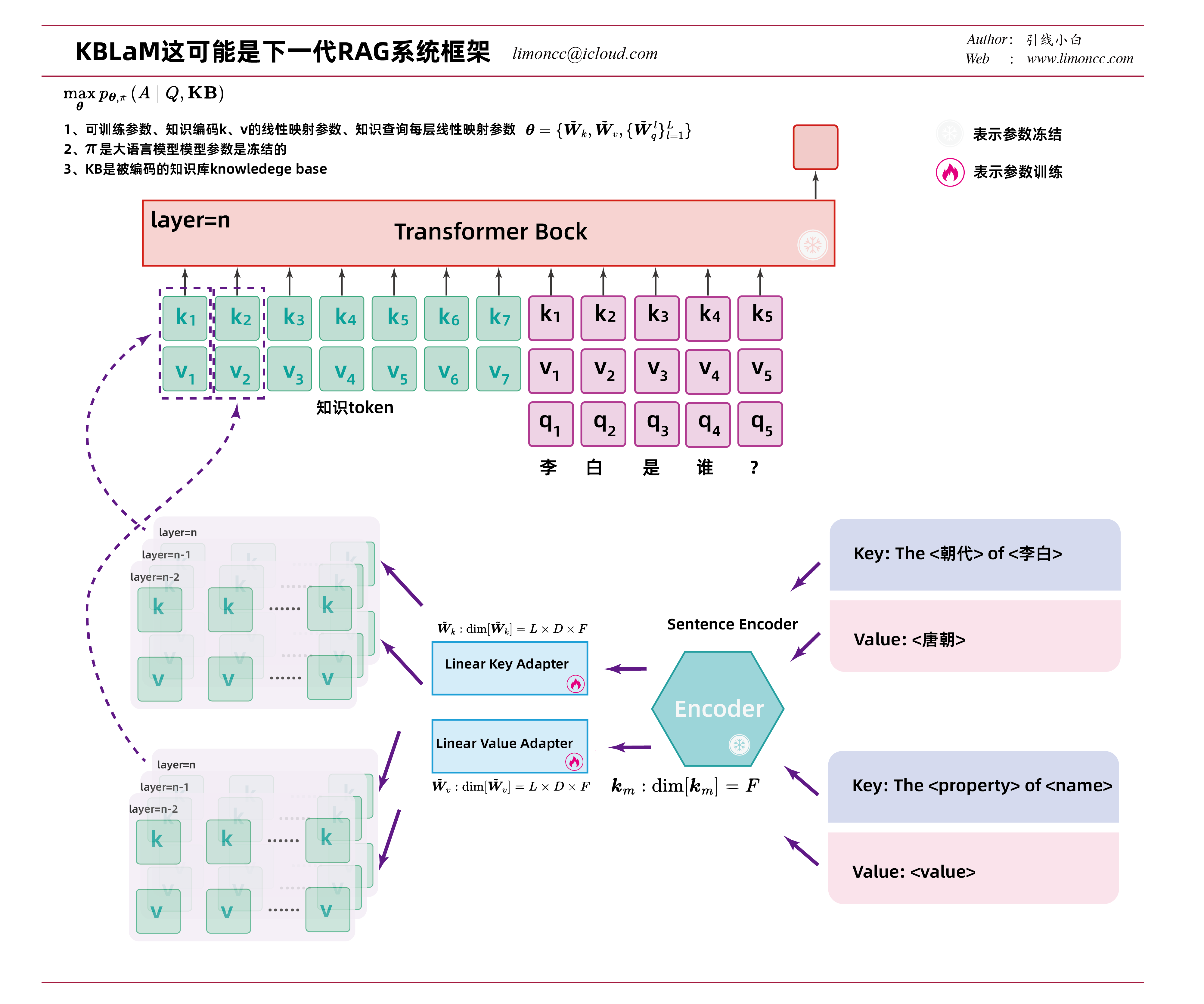
2.1、知识令牌
废话少说,两张图展示其核心原理,说实话现在论文为了在学术上讲故事,说人话是很难的说。核心步骤:
1、将每个三元组映射为一个固定长度的KV向量对,称为知识令牌
2、其中k是使用一个现成的嵌入模型,论文用的是OpenAI的ada-002 sentence embedding model生成一个F维嵌入向量,然后使用一个线性层$\displaystyle \tilde{\bm{W}}_{k}:\dim[\tilde{\bm{W}}_{k}] = L\times D\times F$,将这个嵌入向量映射为模型每层的需要的k
3、知识令牌的v和k一样,不过使用一个线性层$\displaystyle \tilde{\bm{W}}_{v}:\dim[\tilde{\bm{W}}_{v}] = L\times D\times F$来实现
4、也就是说每个知识令牌对应一组kv,如第m个知识 $knowledge_m:=\{\bm{k}_{embed},\bm{v}_{embed}\}
\mathop{\Longrightarrow}_{\tilde{\bm{W}}_{k},\tilde{\bm{W}}_{v}}\Longrightarrow\{\tilde{\bm{k}}_m^l,\tilde{\bm{v}}_m^l\}_{l=1}^L$
如下图所示,对于「李白的朝代时唐朝」这个知识会被结构化为
1、$
2、知识令牌中的Key_embed=BGM-M3(李白的朝代)
3、知识令牌中的value_embed=BGM-M3(唐朝)
4、然后会通过两个线性层映射到LLM模型每一层的KV上去。
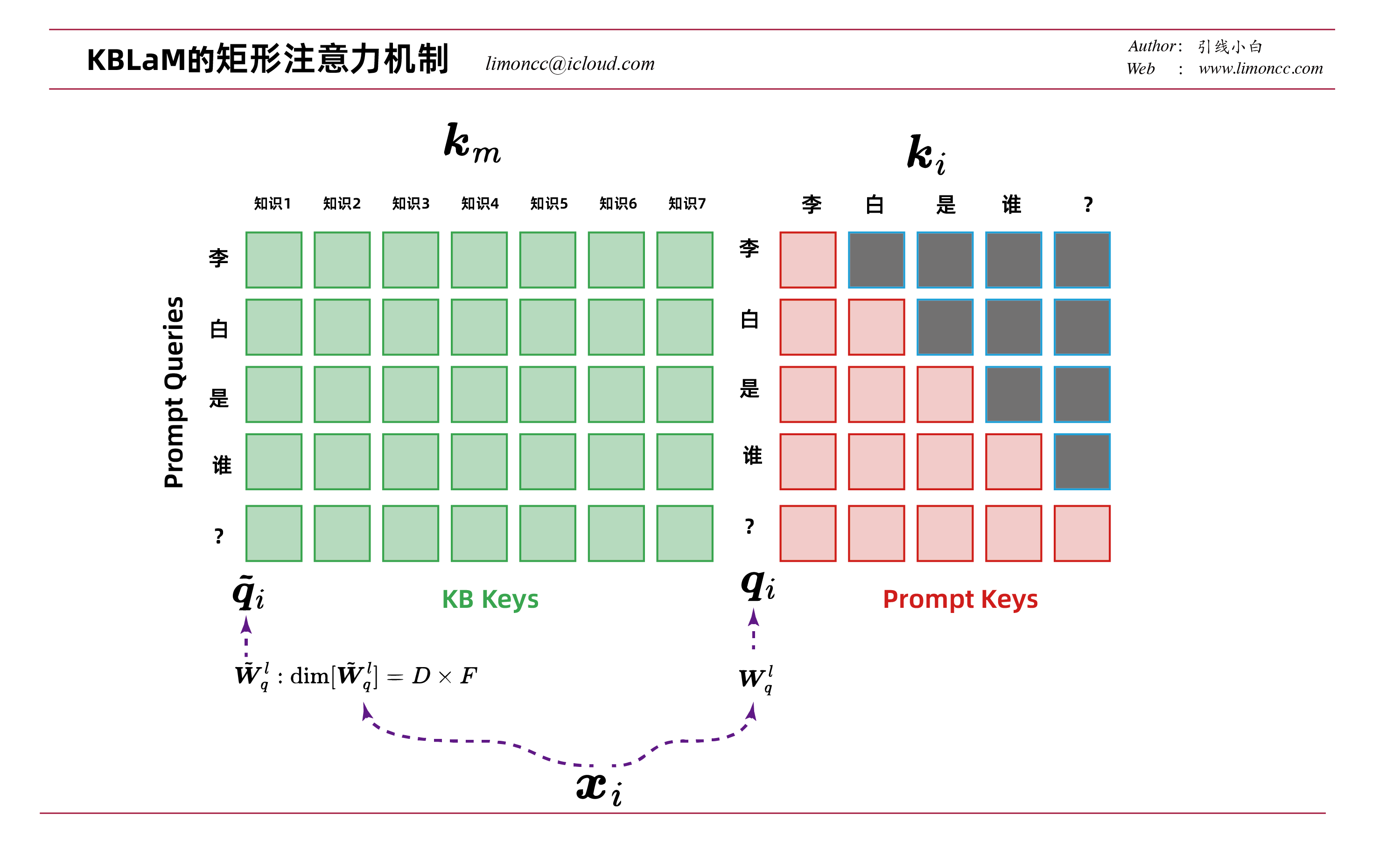
2.2、矩形注意力
KBLAM通过使用简单的矩形注意力结构,以可扩展和动态的方式利用三元组之间的结构来增强LLM的注意力。具有不同特性的三元组可以被视为独立的信息片段,每个三元组的知识令牌可以独立编码并注入预训练的LLM中。下面笔者来详细解释一下。
1、通常在LLM的注意力是一个方阵,也就是正方形的。外部知识引入只是为了更好的回答问题Q,我们不需要用外部知识之前交互。于是就形成了一个矩形的注意力结构
2、注意这个矩形注意力计算是分开的,它们并不共享同一个 $\bm{Q}$。因为为了适应外部知识,在原有LLM的基础上,每一层在注意力计算时都引入了新的参数 $\tilde{\bm{W}}_q^l$
这种方式使得只需要极少的模型改动。就能给模型高效注入知识。比起现在充满各种规则和人为编写的RAG来说,只需要注入知识和简单微调模型来适应这种注入的知识即可。至于模型如何检索如何整合知识,这是模型自己的事情。从而实现外部知识的端到端处理。当然目前的KBALM对知识的处理和现有LLM的整合还比较粗糙,但这不妨碍我们引入更好的模块来改进KBALM。
不难计算矩形注意力的时间复杂度 $(M+N)ND$,其中M是知识的数量,N是输入tokens数,D是隐藏维度。由于 $M\gg N$计算复杂度只和知识库数量成线性关系。
2.3、矩形注意力的问题
对于每一层的注意力输出
$$\begin{align}
\bm{y} = \frac{\sum_{m=1}^M \exp(\tilde{s}_{n,m})\tilde{\bm{v}}_m+\sum_{i=1}^n \exp(s_{n,i})\bm{v}_i}{\sum_{m=1}^M\exp(\tilde{s}_{n,m})+\sum_{i=1}^n \exp(s_{n,i})}
\end{align}$$
由于 $M\gg N$必然稀释对输入tokens的注意力
$$\begin{align}
\tilde{s}_{n,m} = \frac{\langle \tilde{\bm{q}}_n, \tilde{\bm{k}}_m \rangle}{\sqrt{D}}
\end{align}$$
知识令牌的注意力分数总和$\sum_{m=1}^M \exp(\tilde{s}_{n,m})$可能远超过提示令牌的总和$\sum_{i=1}^n \exp(s_{n,i})$。这将导致模型过度依赖知识库,而忽略输入提示的上下文。论文通过超参数 $C$控制知识令牌的总贡献比例,使其与提示令牌保持平衡。
$$\begin{align}
&\exp\left( \log C - \log M + \tilde{s}_{n,m} \right)\\
&=\exp\left( \log \left( \frac{C}{M} \right) + \tilde{s}_{n,m} \right)\
&= \frac{C}{M} \cdot \exp(\tilde{s}_{n,m})
\end{align}$$
- 当 $M$增大时,$\frac{1}{M}$减小,但总和仍通过 $C$控制上限。
- 通过设置超参数(C)(如(C=100)),知识部分的总权重近似为$C \cdot \text{Average attention}$,而提示部分为 $n \cdot \text{Average attention}$。调整$C$可控制知识库的贡献强度。
- $C$相当于人为设定的“虚拟知识令牌数量”。例如,$C=100$表示无论实际知识令牌数 $M$多大,模型将知识的总权重视为等效于100个高相关性的令牌。
- 当 $M \ll C$:每个知识令牌的权重被放大($\frac{C}{M} > 1$),强化知识影响。
- 当 $M \gg C$:每个知识令牌的权重被抑制($\frac{C}{M} \ll 1$),防止知识淹没提示。
三、如何训练
理解了上述原理,如何KBALM就呼之欲出了,这里笔者总结一下论文中的细节。
3.1、数据情况
3.1.1、知识库
1、通过GPT-4生成
2、数据结构有45,000个实体名称(由30种对象类型 × 30种概念类型组合生成,例如”restaurant_name + natural_phenomenon”,每个实体包含3个属性(”description”, “objectives”, “purpose”)
3、三元组总数: 45,000(实体) $\times$ 3$\times$(属性/实体) = 135,000个知识三元组
3、数据分配:
训练集:前120,000个三元组(占比89%)
验证集:后15,000个三元组(占比11%)
3.1.2、指令数据集
1、问题类型:
- 简单问答:单实体单属性(如“XX餐厅的描述是什么?”)。
- 多实体问答:涉及多个实体的组合问题(如“比较A和B的目的”)。
- 开放式推理:需要结合知识库的开放式问题(如“XX工具的目标是否可行?请解释”)。
- 不可回答问题:知识库中无相关信息的提问(模型需回答“无法找到相关信息”)。
2、答案生成:
- 简单/多实体问题:通过模板生成答案(直接提取属性值)。
- 开放式问题:使用GPT-4生成参考答案。
- 不可回答问题:固定拒绝回答模板。
3.2、超参数配置
优化器:AdamW,初始学习率$5\times10^{-4}$,余弦退火至$5\times10^{-6}$。
硬件:单块A100 80GB GPU,微批次(micro-batch)大小20,累计批次大小400。
训练步数:20,000次迭代(约2-3天)
动态知识库采样:每个训练样本从合成KB中随机抽取10-100个三元组作为当前KB,其中:
- 正例:随机选择1个或多个三元组作为问题答案的依据。
- 负例:剩余三元组作为干扰项。
混合问题类型:每批次包含不同问题类型(如20%不可回答问题,其余混合)。
四、评述
1、论文指出,KBLAM的知识令牌将三元组中的句子编码为固定长度的向量,因此KBLAM可能无法精确地逐词生成文本。对于这个问题,笔者认为引入诸如gte-qwen2-7b-instruct的模型可以动态编码知识。
2、对于KBLAM知识三元组,例如「爱因斯坦的物理学贡献是相对论」,训练一个知识的属性编码器,来表示抽象语义(如”成就类型”);训练一个值编码器保留细节(如具体理论名称)。而不是KBLAM中的硬编码三元组
3、对于矩形注意力的计算问题,目前KBLAM是没有做筛选的,即全部知识都参与计算。笔者认为可以加入一种动态因果掩码的机制在动态筛选知识,而不是全部知识参与计算。
4、随着KBLAM后续改进模型的出现,嵌入外部知识将会有更多的新选择,而传统RAG的优势还有多少,大家拭目以待。尤其是线性注意力模型的兴起,将极大改变现有技术范式。
5、历史终将证明复杂工程化注定会被模型碾碎,依靠强化学习提升模型端到端能力将比工作流加知识库越来越有竞争力。
[^1]: Wang, X., Isazawa, T., Mikaelyan, L., & Hensman, J. (2025, February 9). KBLaM: Knowledge Base augmented Language Model. arXiv. https://doi.org/10.48550/arXiv.2410.10450
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/6c5064b1a9544809/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Mar. 21, 2025). 《KBALM-知识库增强型语言模型-大语言模型研究07》[Blog post]. Retrieved from https://www.limoncc.com/post/6c5064b1a9544809 |
| @online{limoncc-6c5064b1a9544809, title={KBALM-知识库增强型语言模型-大语言模型研究07}, author={引线小白}, year={2025}, month={Mar}, date={21}, url={\url{https://www.limoncc.com/post/6c5064b1a9544809}}, } |