作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/9b154bbdc2a51d2ea34ec070684b5132/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
摘要:本文意在理清隐马尔可夫模型的问题。若有错误,请大家指正。
关键词:隐马尔可夫模型,前向-后向算法,维特比算法,鲍姆-韦尔奇算法
一、马尔可夫模型
1.1、基本概念
1.1.1、符号
我们开始讨论,离散时间离散状态,也就是离散随机序列。假定:离散时间: $\displaystyle \{1,\cdots,T\}$;离散状态:$\displaystyle x_t\in \{1,\cdots,c,\cdots,C\}$。我们称
$$\begin{align}
p(\bm{x}_{1:T})=p(x_1)\prod_{t=2}^Tp\big(x_t\mid x_{t-1}\big)
\end{align}$$
为一阶马尔可夫模型。下面来初步认识一下这个模型。
1.1.2、转移概率
转移概率: 从状态 $\displaystyle i$到状态 $\displaystyle j$的概率 $\displaystyle A_{ij}=p\big(x_t=j\mid x_{t-1}=i\big)$,于是有转移矩阵$\displaystyle \bm{A}=\big[A_{ij}\big]$,且有 $\displaystyle \sum_{j=1}^KA_{ij}=\bm{I}^\text{T}\bm{a}_i=1$ 也就说 $\displaystyle \bm{A}$的每一行相加等于1。这样的矩阵我们称之为随机矩阵 $\displaystyle \textit{(stochastic matrix)}$。注意这个时候我们定义的转移矩阵与离散的时间没有关系。
下面我们定义第 $\displaystyle n$步转移矩阵:$\displaystyle A_{ij}\big(n\big)=p\big(x_{t+n}=j\mid x_{t}=i\big)$,已知 $\displaystyle \bm{A}(1)=\bm{A}$,我们有查普曼-柯尔莫哥洛夫等式 $\displaystyle \textit{(Chapman-Kolmogorov equations)}$
$$\begin{align}
A_{ij}(m+n)=\sum_{k=1}^KA_{ik}(m)A_{kj}(n)
\end{align}$$亦有:
$$\begin{align}
\bm{A}(m+n)=\bm{A}(m)\bm{A}(n)
\end{align}$$
于是有 $\displaystyle \bm{A}(n)=\bm{A}\bm{A}(n-1)=\bm{A}\bm{A}\bm{A}(n-2)=\cdots=\bm{A}^n$
1.2、应用
马尔可夫模型可以用于多个领域。例如把词序列看成是概率分布,状态空间是所有词的集合。我们可以定义一元模型、二元模型、三元模型、$\displaystyle n$ 元模型。进而可用于这些领域:句子补全、数据压缩、文本分类、自动写作等
1.3、极大似然法与二元模型马尔可夫过程
考虑单变量历史状态模型 $\displaystyle x_t\in\{1,\cdots,C\}$,同时定义一条链的数据集合 $\displaystyle x_{1:T}=\bm{x}$ 有:
$$\begin{align}
p\big(x_{1:T}\mid \bm{\pi},\bm{A}\big)
&=p\big(x_1\big)A\big(x_1,x_2\big)\cdots A\big(x_{T-1},x_{T}\big)\\
p\big(\bm{x}\mid \bm{\pi},\bm{A}\big)&=\mathrm{Cat}\big(x_1\mid\bm{\pi}\big)\cdots A\big(x_{T-1},x_{T}\big)\\
&=\prod_{c=1}^C\pi_c^{\mathbb{I}(x_1=c)}\cdot\prod_{t=2}^T\prod_{c=1}^C\prod_{s=1}^CA_{cs}^{\mathbb{I}\left(x_t=s,x_{t-1}=c\right)}
\end{align}$$
定义:$\displaystyle \bm{x}_i=x_{1:T}^i$,进而定义链的集合 $\displaystyle \mathcal{D}=\{\bm{x}_i\}_{i=1}^N$,有该链集的对数似然函数:
$$\begin{align}
&\ell\big(\mathcal{D}\mid \bm{\pi},\bm{A}\big)
=\ln p\big(\mathcal{D}\mid \bm{\pi},\bm{A}\big) \\
&=\ln \prod_{i=1}^Np\big(\bm{x}_i\mid \bm{\pi},\bm{A}\big)
=\sum_{i=1}^N\ln\left[\prod_{c=1}^K\pi_c^{\mathbb{I}(x_1^i=c)}\prod_{t=2}^T\prod_{c=1}^C\prod_{s=1}^CA_{cs}^{\mathbb{I}\left(x_t^i=s,x_{t-1}^i=c\right)}\right]\\
&=\sum_{i=1}^N\ln \left[\prod_{c=1}^C\pi_c^{\mathbb{I}(x_1^i=c)}\right]+\sum_{i=1}^N\ln \left[\prod_{t=2}^T\prod_{c=1}^C\prod_{s=1}^CA_{cs}^{\mathbb{I}\left(x_t^i=s,x_{t-1}^i=c\right)}\right]\\
&=\sum_{c=1}^C \left[\sum_{i=1}^N\mathbb{I}(x_1^i=c)\ln\pi_c\right]+\sum_{c=1}^C\sum_{s=1}^C \left[\sum_{i=1}^N\sum_{t=2}^T\mathbb{I}\left(x_t^i=s,x_{t-1}^i=c\right)\ln A_{cs}\right]\\
&=\sum_{c=1}^CN_{c}^{1}\ln\pi_c+\sum_{c=1}^C\sum_{s=1}^C N_{cs}\ln A_{cs}\\
&={\bm{N}_1}^\text{T}\ln \bm{\pi}+ \bm{I}^\text{T}\left[\bm{N}\odot\ln\bm{A}\right]\bm{I}
\end{align}$$
其中:$\displaystyle N_c^1=\sum_{i=1}^N\mathbb{I}(x_1^i=c)$,$\displaystyle N_{cs}=\sum_{i=1}^N\sum_{t=2}^T\mathbb{I}\left(x_t^i=s,x_{t-1}^i=c\right)$,且有$\displaystyle \bm{I}^\text{T}\bm{\pi}=1, \bm{A}\bm{I}=\bm{I}$。将约束代入,我们有:
$$\begin{align}
\ell\big(\mathcal{D}\mid \bm{\pi},\bm{A}\big) ={\bm{N}_1}^\text{T}\ln \bm{\pi}+ \bm{I}^\text{T}\left[\bm{N}\odot\ln\bm{A}\right]\bm{I}+\lambda \left[\bm{I}^\text{T}\bm{\pi}-1\right]+ \left[\bm{A}\bm{I}-\bm{I}\right]^\text{T}\bm{\delta}
\end{align}$$
于是求先验概率参数有:
$$\begin{align}
\frac{\partial \ell}{\partial \bm{\pi}}&=\frac{\bm{N}_1}{\bm{\pi}}+\lambda \bm{I}=0\\
\frac{\partial \ell}{\partial \lambda}&=\bm{I}^\text{T}\bm{\pi}-1=0
\end{align}$$得 $$\begin{align}
\bm{\pi}=\frac{\bm{N}_1}{\bm{I}^\text{T}\bm{N}_1}
\end{align}$$
又求转移概率有:
$$\begin{align}
\frac{\partial \ell}{\partial \bm{A}}=\frac{\bm{I}\bm{I}^\text{T}\odot\bm{N}}{\bm{A}}+ \bm{I}^\text{T}\bm{\delta}=\frac{\bm{N}}{\bm{A}}+\bm{I}^\text{T}\bm{\delta}=\bm{0}\\
\frac{\partial \ell}{\partial \bm{\delta}}&=\bm{A}\bm{I}-\bm{I}=\bm{0}
\end{align}$$
得
$$\begin{align}
\bm{A}=\frac{\bm{N}}{\bm{N}\bm{I}}=\frac{\bm{N}}{\bm{N}_c}
\end{align}$$
我们注意到:对于 $\displaystyle n$元模型 参数将会指数级增加 $\displaystyle O(C^n)$。对于5万个单词的语言模型,参数将到达惊人的25亿。显然我们是无法凑齐足够多数据,来使用极大似然法求参数。我们将面临严重的 零数问题。
1.4、平滑方法
1.4.1、拉普拉斯加一平滑
当然我们可以使用 拉普拉斯加一平滑。当这不是唯一平滑的方法。
1.4.2、删除插值
$$\begin{align}
A=(1-\lambda)\frac{N_{cs}}{N_c}+\lambda \frac{N_s}{N}
\end{align}$$
删除插值约等于一个贝叶斯模型,假设一个狄利克雷先验,易得之
1.4.3、古德-图灵估计与卡茨退避法
我们有 古德-图灵估计 $\displaystyle \textit{(Good-Turing Estimate)}$
二、隐马尔可夫模型
2.1、基本定义
1、隐变量的一阶马尔可夫假设 $\displaystyle p\big(z_t\mid z_{t-1},\cdots,z_1\big)=p\big(z_t\mid z_{t-1}\big)$
2、观测变量的独立假设 $\displaystyle p\big(\bm{x}_t\mid \bm{x}_{t-1},\cdots,\bm{x}_1,z_t,\cdots,z_1\big)=p \big(\bm{x}_t\mid z_t\big)$
隐变量数据集 $\displaystyle \mathcal{D}_T^z=\{z_t\}_{t=1}^T$,观测变量数据集 $\displaystyle \mathcal{D}_T^\bm{x}=\{\bm{x}_t\}_{t=1}^T$,完全数据集 $\displaystyle \mathcal{D}^+_T=\{\mathcal{D}_T^\bm{x},\mathcal{D}_T^z\}$,且有:
$$\begin{align}
p \big(\mathcal{D}_T^+\big)
=p\big(\mathcal{D}_T^\bm{x},\mathcal{D}_T^z\big)
=p\big(\mathcal{D}_T^\bm{x}\mid \mathcal{D}_T^z\big)p\big(\mathcal{D}^z\big)
\end{align}$$
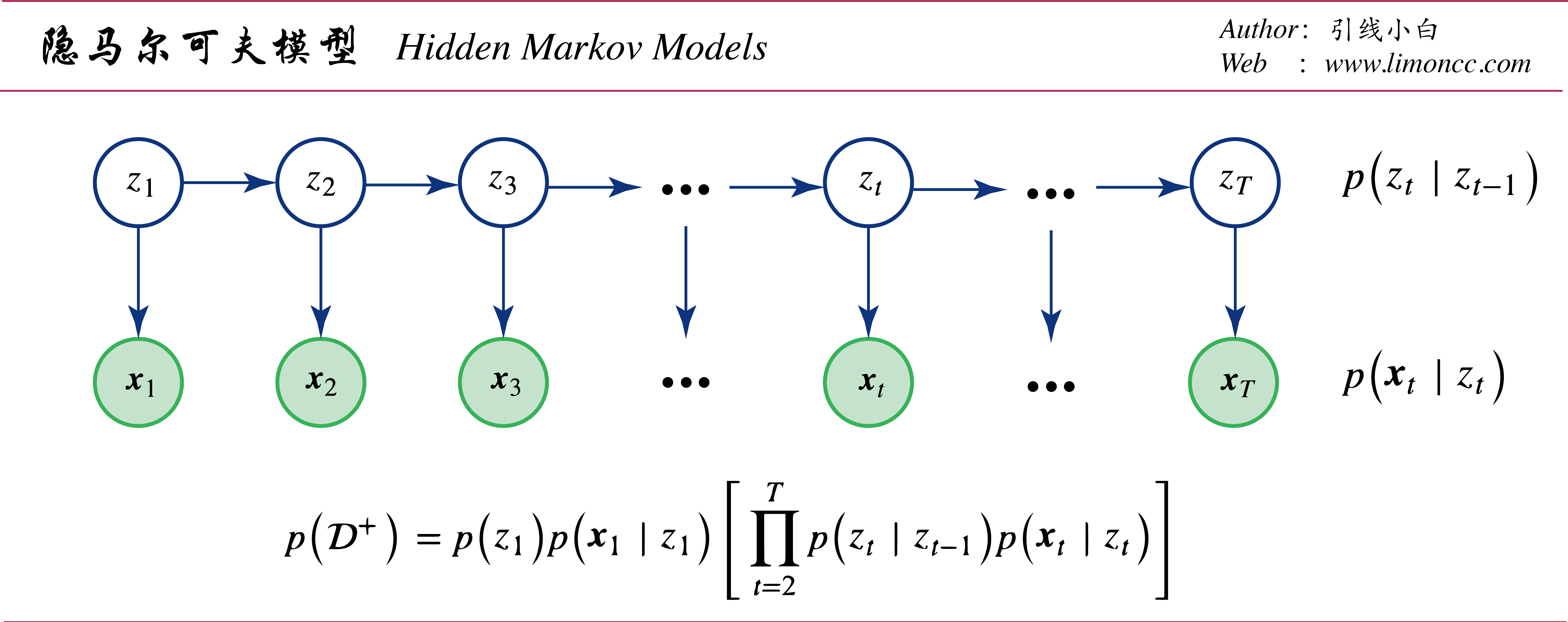
隐马尔可夫模型
为了简洁记,我们来定义一些符号。考虑隐变量有 $\displaystyle K$个状态 $\displaystyle z_t\in\{1,\cdots,K\}$,观测变量有 $\displaystyle O$个状态 $\displaystyle \bm{x}_t\in\{1,\cdots,O\}$。注意这里形式化的使用 $ o$来表示向量 $ \bm{x}_t$的状态,也就是说我们并没有定义向量是什么,因为这样能节约符号,和叙述上不必要的麻烦。继续定义若干参数:
$\displaystyle \pi[i]=p(z_1=i)$
$\displaystyle A[i,j]=p(z_t=j\mid z_{t-1}=i)$
$\displaystyle B[i,o]=p(\bm{x}_t=o\mid z_t=i)$
令参数集合为:
$$\begin{align}
\bm{\theta}=\{\bm{\pi},\bm{A},\bm{B}\}
\end{align}$$
注意这里的 $ \bm{\theta}$应该做形式化的理解,它既不是矩阵,也不是向量,而是一个相当于集合符号。在机器学习领域 $ \bm{\theta}$经常被用来表示参数,不对其不加具体定义。而对于观测变量是连续的,我们定义条件概率分布 $\displaystyle \rho_t[i]=p\big(\bm{x}_t\mid z_t=i\big)$ ,注意如果 $\displaystyle \bm{x}_t$未知,则 $\displaystyle \rho_t[i]$是个概率分布。而如果我们有数据集 $\displaystyle \mathcal{D}_t^{\bm{x}}=\{\bm{x}_1,\cdots,\bm{x}_t\}$, 也就说 $\displaystyle \bm{x}_t$已知,那么 $\displaystyle \rho_t[i]$是个数。那么参数集合是:
$$\begin{align}
\bm{\theta}=\{\bm{\pi},\bm{A},\bm{\rho}_t\}
\end{align}$$
注意:关于符号 $\displaystyle p(x)$和 $\displaystyle p(x=a)$的解释,这时的符号 $\displaystyle p$有点点转换。由一个函数变成了一个数。
2.2、向前向后算法
2.2.1、直接计算
我们要解决如何高效求观测变量数据集联合分布的问题,下面我们要分析一下这个基本问题。考虑离散隐变量 $\displaystyle z_t$,离散观测变量 $\displaystyle x_t$,这时隐马尔可夫模型观测数据集 $\displaystyle \mathcal{D}_T^{\bm{x}}=\{\bm{x}_t=o(t)\}_{t=1}^T$:
$$\begin{align}
p\big(\mathcal{D}_T^\bm{x},\mathcal{D}_T^z\big)=p\big(\mathcal{D}_T^\bm{x}\mid \mathcal{D}_T^z\big)p\big(\mathcal{D}_T^z\big)=p\big(z_1\big)p\big(\bm{x}_1\mid z_1\big)\Bigg[\prod_{t=2}^Tp\big(z_t\mid z_{t-1}\big)p\big(\bm{x}_t\mid z_t\big)\Bigg]
\end{align}$$整理写成:
$$\begin{align}
&p\big(\mathcal{D}_T^\bm{x}\mid \bm{\theta}\big)=\sum_{i(1)=1}^K \cdots\sum_{i(T)=1}^K p\big(\mathcal{D}_T^{\bm{x}},\mathcal{D}_T^z\mid \bm{\theta}\big)\\
&=\sum_{i(1)=1}^K \cdots\sum_{i(T)=1}^K \left[\Bigg[p(z_1)\prod_{t=2}^Tp\big(z_t\mid z_{t-1}\big)\Bigg]\Bigg[\prod_{t=1}^Tp\big(x_t\mid z_t\big)\Bigg]\right]\\
&=\sum_{i(1)=1}^K \cdots\sum_{i(T)=1}^K \left[\pi\big[i(1)\big]\cdot\prod_{t=2}^TA_t\big[i(t-1),i(t)\big]\cdot\prod_{t=1}^TB_t\big[i(t),o(t)\big]\right]\\
&=\sum_{i(1)=1}^K\cdots\sum_{i(T)=1}^K\Bigg[\pi\big[i(1)\big]B_1\big[i(1),o(1)\big]\cdot\prod_{t=2}^T \bigg[A_t\big[i(t-1),i(t)\big]\cdot B_t\big[i(t),o(t)\big]\bigg]\Bigg]
\end{align}$$
观察一下大中括号里面的式子
$$\begin{align}
\pi\big[i(1)\big]B_1\big[i(1),o(1)\big]A_2\big[i(1),i(2)\big] B_2\big[i(2),o(2)\big]\cdots A_T\big[i(T-1),i(T)\big] B_T\big[i(T),o(T)\big]
\end{align}$$
若观测变量是连续的有:
$$\begin{align}
p\big(\mathcal{D}_T^\bm{x}\mid \bm{\theta}\big)=\sum_{i_1=1}^K\cdots\sum_{i_T=1}^K\Bigg[\pi[i_1]\rho_1[i_1]\cdot\prod_{t=2}^T \bigg[A_t[i_{t-1},i_{t}]\cdot \rho_t[i_t]\bigg]\Bigg]
\end{align}$$
这个方法的计算复杂度是 $\displaystyle O\big({2TK}^T\big)$, 例如 $\displaystyle K=5,T=10$,那么就要约计算 $\displaystyle 1.95\times10^8$已经非常夸张了。为了更快的计算观测变量的联合分布,我们需要充分利用隐马尔可夫的性质:
2.2.2、前向算法
现在定义一个新的数据集,或者叫做在线数据集 $\displaystyle \mathcal{D}_t^{\bm{x}}=\{\bm{x}_i\}_{i=1}^t$我们定义 $\displaystyle \alpha_t[j]=p\big(\mathcal{D}_{t}^\bm{x}, z_{t}=j\big)$于是有:
$$\begin{align}\require{cancel}
&\alpha_{t}[j]=p\big(\mathcal{D}_t^{\bm{x}},z_t=j)
=p \big(\mathcal{D}_t^{\bm{x}}\mid z_t=j\big)p \big(z_t=j\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)p \big(\mathcal{D}_{t-1}^{\bm{x}}\mid z_t=j\big)p \big(z_t=j\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)p \big(\mathcal{D}_{t-1}^{\bm{x}}, z_t=j\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)\sum_{i=1}^Kp \big(\mathcal{D}_{t-1}^{\bm{x}},z_t=j,z_{t-1}=i\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)\sum_{i=1}^Kp \big(\mathcal{D}_{t-1}^{\bm{x}},z_t=j\mid z_{t-1}=i\big) p \big(z_{t-1}=i\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)\sum_{i=1}^Kp \big(\mathcal{D}_{t-1}^{\bm{x}}\mid \cancel{z_t=j},z_{t-1}=i\big)p \big(z_t=j\mid z_{t-1}=i\big) p \big(z_{t-1}=i\big)\\
&=p \big(\bm{x}_t\mid z_t=j\big)\sum_{i=1}^Kp \big(\mathcal{D}_{t-1}^{\bm{x}},z_{t-1}=i\big)p \big(z_t=j \mid z_{t-1}=i\big)\\
&=\rho_t[j]\sum_{i=1}^K\bigg[ \alpha_{t-1}[i]A[i,j]\bigg]\\
\end{align}$$
写成矩阵形式有:
$$\begin{align}
\bm{\alpha}_{t}=\bm{\rho}_t\odot\left[\bm{A}^\text{T}\bm{\alpha}_{t-1}\right]
\end{align}$$
于是有观测变量数据集联合分布
$$\begin{align}
p\big(\mathcal{D}_T^{\bm{x}}\mid\bm{\theta}\big)
=\sum_{j=1}^K \alpha_T[j]
=\bm{I}^\text{T}\bm{\alpha}_{T}
\end{align}$$
计算复杂度变为了 $\displaystyle O({TK}^2)$。
2.2.3、前向后向算法。
之前我们定义了 $\displaystyle \alpha_t[j]=p\big(\mathcal{D}_{t}, z_{t}=j\big)$,知道观测变量的条件概率:$\displaystyle \rho_t[j]=p\big(\bm{x}_t\mid z_t=j\big)$。我们再定义未来数据集的条件似然(有些书上也称后向概率)$\displaystyle \beta_t[i]=p\big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_t=i\big)$,利用隐马尔可夫的条件假设,推导得到:
$$\begin{align}\require{cancel}
\beta_{t-1}[i]
&=p\big(\mathcal{D}_{t:T}^{\bm{x}}\mid z_{t-1}=i\big)\\
&=\sum_{j=1}^Kp\big(z_t=j,\bm{x}_t,\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_{t-1}=i\big)\\
&=\sum_{j=1}^Kp\big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_t=j,\cancel{z_{t-1}=i},\cancel{\bm{x}_t}\big)p\big(z_t=j,\bm{x}_t\mid z_{t-1}=i\big)\\
&=\sum_{j=1}^Kp\big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_t=j\big)p\big(\bm{x}_t\mid z_t=j,\cancel{z_{t-1}=i}\big)p\big(z_t=j\mid z_{t-1}=i\big)\\
&=\sum_{j=1}^Kp\big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_t=j\big)p\big(\bm{x}_t\mid z_t=j\big)p\big(z_t=j\mid z_{t-1}=i\big)\\
&=\sum_{j=1}^K\beta_{t}[j]\cdot\rho_t[j]\cdot A[i,j]
\end{align}$$写成矩阵形式。
$$\begin{align}
\bm{\beta}_{t-1}=\bm{A} \left[\,\bm{\rho}_t\odot\bm{\beta}_t\right]
\end{align}$$
其中有 $\displaystyle \beta_{T}[i]=p\big(\mathcal{D}_{T+1:T}^{\bm{x}}\mid z_T=i\big)
=p \big(\emptyset\mid z_T=i\big)=1$,于是有 $\displaystyle \bm{\beta}_T=\bm{I}$
用这个似然和初始概率计算观测变量数据集联合分布有:
$$\begin{align}
p\big(\mathcal{D}_T^{\bm{x}}\mid\bm{\theta}\big)
= \sum_{i=1}^K\alpha_1[i]\beta_1[i]
=\sum_{i=1}^K\alpha_t[i]\beta_t[i]
=\bm{I}^\text{T}\big[\bm{\alpha}_t\odot\bm{\beta}_{t}\big]=\bm{I}^\text{T}\bm{\alpha}_{T}
\end{align}$$
2.2.5、隐变量后验边际概率
定义隐变量后验边际概率 $\displaystyle \eta_t[j]=p\big(z_t=j\mid \mathcal{D}_T\big)$,这个概率对我们颇为重要,下面使用向前向后算法计算它
$$\begin{align}
\eta_t[j]
&=p\big(z_t=j\mid \mathcal{D}_T^{\bm{x}}\big)
=\frac{p \big(\mathcal{D}_T^{\bm{x}}\mid z_t=j\big)p \big(z_t=j\big)}{p \big(\mathcal{D}_T\big)}\\
&=\frac{p \big(\mathcal{D}_t^{\bm{x}}\mid z_t=j\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid z_t=j\big)p \big(z_t=j\big)}{p \big(\mathcal{D}_T^{\bm{x}}\big)}
=\frac{p \big(\mathcal{D}_t^{\bm{x}}\mid z_t=j\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}, z_t=j\big)}{p \big(\mathcal{D}_T^{\bm{x}}\big)}\\
&=\frac{\alpha_t[j]\cdot\beta_t[j]}{\displaystyle\sum_{i=1}^K \alpha_t[j]\cdot\beta_t[j]}
\propto \alpha_t[j]\cdot\beta_t[j]
\end{align}$$写成矩阵形式
$$\begin{align}
\bm{\eta}_t
= \frac{\bm{\alpha}_t\odot \bm{\beta}_t}{\bm{I}^\text{T}\big[\bm{\alpha}_t\odot \bm{\beta}_t\big]}
\propto \bm{\alpha}_t\odot \bm{\beta}_t
\end{align}$$
2.2.4、隐变量两点边际概率
隐变量两点边际概率在模型的参数估计中有重要应用,使用向前向后算法可以计算它
$$\begin{align}
p \big(\bm{z}_{t-1}, \bm{z}_t\mid \mathcal{D}_T^\bm{x}\big)
=\frac{p \big(\mathcal{D}_T^\bm{x}\mid\bm{z}_{t-1},\bm{z}_t\big)p \big(\bm{z}_{t-1},\bm{z}_t\big)}{p \big(\mathcal{D}_T^\bm{x}\big)}
=\frac{p \big(\mathcal{D}_T^\bm{x}\mid\bm{z}_{t-1},\bm{z}_t\big)p \big(\bm{z}_t\mid \bm{z}_{t-1}\big)p\big(\bm{z}_{t-1}\big)}{p \big(\mathcal{D}_T^\bm{x}\big)}
\end{align}$$
单独考虑
$$\begin{align}\require{cancel}
p \big(\mathcal{D}_T^\bm{x}\mid\bm{z}_{t-1},\bm{z}_t\big)
&=p \big(\mathcal{D}_{t-1}^{\bm{x}},\bm{x}_t,\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_{t-1},\bm{z}_t\big)\\
&=p \big(\mathcal{D}_{t-1}^{\bm{x}},\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_{t-1},\bm{z}_t\big)p \big(\bm{x}_t\mid\cancel{\bm{z}_{t-1}},\bm{z}_t\big)\\
&=p \big(\mathcal{D}_{t-1}^{\bm{x}}\mid\bm{z}_{t-1},\cancel{\bm{z}_t}\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid\cancel{\bm{z}_{t-1}},\bm{z}_t\big)p \big(\bm{x}_t\mid\bm{z}_t\big)\\
&=p \big(\mathcal{D}_{t-1}^{\bm{x}}\mid\bm{z}_{t-1}\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_t\big)p \big(\bm{x}_t\mid\bm{z}_t\big)
\end{align}$$
代入得到
$$\begin{align}
p \big(\bm{z}_{t-1}, \bm{z}_t\mid \mathcal{D}_T^\bm{x}\big)
&=\frac{p \big(\mathcal{D}_{t-1}^{\bm{x}}\mid\bm{z}_{t-1}\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_t\big)p \big(\bm{x}_t\mid\bm{z}_t\big)p \big(\bm{z}_t\mid \bm{z}_{t-1}\big)p\big(\bm{z}_{t-1}\big)}{p \big(\mathcal{D}_T^\bm{x}\big)}\\
&=\frac{p \big(\mathcal{D}_{t-1}^{\bm{x}},\bm{z}_{t-1}\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_t\big)p \big(\bm{x}_t\mid\bm{z}_t\big)p \big(\bm{z}_t\mid \bm{z}_{t-1}\big)}{p \big(\mathcal{D}_T^\bm{x}\big)}\\
&=\frac{p \big(\bm{z}_t\mid \bm{z}_{t-1}\big)p \big(\mathcal{D}_{t-1}^{\bm{x}},\bm{z}_{t-1}\big)p \big(\bm{x}_t\mid\bm{z}_t\big)p \big(\mathcal{D}_{t+1:T}^{\bm{x}}\mid\bm{z}_t\big)}{p \big(\mathcal{D}_T^\bm{x}\big)}\\
\end{align}$$
我们令 $\displaystyle \xi_{t}[i,j]=p\big(z_{t-1}=i,z_t=j\mid \mathcal{D}_T^\bm{x}\big)$则有:
$$\begin{align}
\xi_{t}[i,j]\propto A[i,j]\cdot\alpha_{t-1}[i]\cdot\rho_{t}[j]\cdot\beta_t[j]
\end{align}$$
如果同时令 $\displaystyle \bm{Z}_t=\bm{z}_{t-1}\bm{z}_t^\text{T}$, $\displaystyle \bm{\varXi}_t=\big[\xi_{t}[i,j]\big]$。亦有 $\displaystyle \bm{Z}_t\sim \mathrm{Cat} \big(\bm{Z}_t\mid \bm{\varXi}_t\big)$,注意这是一个矩阵分类分布。
$$\begin{align}
\mathrm{E}_q\big[\bm{Z}_t\big]=\mathrm{E}_q\big[\bm{z}_{t-1}\bm{z}_t^\text{T}\big]=\sum_{\bm{Z}\in\{0,1\}^{K\times K}} \bm{Z}_t \mathrm{Cat} \big(\bm{Z}_t\mid \bm{\varXi}_t\big)=\bm{\varXi}_t=\frac{\bm{A}\odot\bigg[\bm{\alpha}_{t-1}\big[\bm{\rho}_t\odot \bm{\beta}_t\big]^\text{T}\bigg]}{\bm{I}^\text{T}\big[\bm{\alpha}_t\odot\bm{\beta}_{t}\big]}
\end{align}$$
也就说 $\displaystyle \mathrm{E}_q\big[z_{t-1}=i,z_t=j\big]=\xi_{t}[i,j]$。
2.3、鲍姆-韦尔奇算法
2.3.1、完全数据集对数似然函数期望
对于隐变量我们有 $\displaystyle \mathcal{D}_T^z=\{z_t\}_{t=1}^T$, $\displaystyle z_t\in \{1,\cdots,K\}$。现在我们要改变隐变量符号的表示方法,即 $\displaystyle \mathcal{D}_T^\bm{z}=\{\bm{z}_t\}_{t=1}^T$, $\displaystyle \bm{z}_t\in \{0,1\}^K$。这个向量表示方法与之前的表示方法是等价的,务必熟悉这两个表示方法。
$$\begin{align}
\bm{z}_t=[ 0\cdots1\cdots0 ]^\text{T}\iff \bm{z}_t[k]=z_{tk}=1\iff z_t=k
\end{align}$$
我们有隐变量初始先验分布、观测变量条件分布、转移概率。
$$\begin{align}\begin{cases}
p \big(\bm{z}_t\mid \bm{\pi}\big)&\displaystyle=\mathrm{Cat} \big(\bm{z}_t\mid \bm{\pi}\big)=\prod_{k=1}^K\pi_k^{z_t[k]}\\
p \big(\bm{x}_t\mid \bm{z}_t,\bm{\varphi}\big)&\displaystyle=\prod_{i=1}^Kp \big(\bm{x}_t\mid \varphi_i\big)^{z_t[i]}\\
p \big(\bm{z}_t\mid \bm{z}_{t-1},\bm{A}\big)&\displaystyle=\prod_{i=1}^K\prod_{j=1}^K A_{ij}^{z_t[i]z_{t-1}[j]}
\end{cases}\end{align}$$
代入有联合概率分布:
$$\begin{align}
p \big(\mathcal{D}_T^+\big)
&=p\big(\bm{z}_1\big)p\big(\bm{x}_1\mid z_1\big)\Bigg[\prod_{t=2}^Tp\big(\bm{z}_t\mid \bm{z}_{t-1}\big)p\big(\bm{x}_t\mid \bm{z}_t\big)\Bigg]\\
&=\prod_{k=1}^K\pi_k^{z_1[k]}\prod_{k=1}^Kp \big(\bm{x}_1\mid\varphi_k\big)^{z_1[k]}\left[\prod_{t=2}^T\Bigg[\prod_{i=1}^K\prod_{j=1}^K A_{ij}^{z_{t-1}[i]z_{t}[j]}\prod_{j=1}^Kp \big(\bm{x}_t\mid\varphi_j\big)^{z_t[j]}\Bigg]\right]
\end{align}$$
同时我们有 $\displaystyle q=q \big(\mathcal{D}_T^\bm{z}\mid \mathcal{D}_T^\bm{x},\theta\big)$。 为简洁记,我们定义一个数 $\displaystyle \eta_t[j]=p\big(z_t=j\mid \mathcal{D}_T^\bm{x}\big)$,是隐变量后验边际概率。这样有 $\displaystyle p\big(\bm{z}_t\mid \mathcal{D}_T^\bm{x}\big)=\mathrm{Cat} \big(\bm{z}_t\mid \bm{\eta}_t\big)=\prod_{j=1}^K\big(\eta_t[j]\big)^{z_t[j]}$。根据 $\displaystyle \textit{EM}$算法,我们来推导一下完全数据集对数似然函数期望具体表示形式。
$$\begin{align}
&\ell \big(\mathcal{D}_T^\bm{x}\mid \theta\big)=\ln p \big(\mathcal{D}_T^\bm{x}\mid \theta\big)
=\mathrm{E}_{q}\big[\ell\big(\mathcal{D}_T^+\mid\theta\big)\big]+\mathrm{H}\big[q\big]+\mathrm{KL}\big[q\parallel p\big]\\
&\propto\mathrm{E}_{q}\big[\ln p\big(\mathcal{D}_T^+\mid \theta\big)\big]
=\mathrm{E}^\text{T}[\bm{z}_1]\ln\bm{\pi}+\sum_{t=1}^T\sum_{k=1}^K\mathrm{E}\big[z_t[k]\big]\ln p \big(\bm{x}_t\mid \varphi_k\big)+\sum_{t=2}^T\bm{I}^\text{T}\left[\mathrm{E}\big[\bm{Z}_t\big]\odot\ln\bm{A}\right]\bm{I}\\
&=\bm{\eta}_1^\text{T}\ln\bm{\pi}+\sum_{t=1}^T\bm{\eta}_t^\text{T}\ln \bm{\rho}_t+\sum_{t=2}^T\bm{I}^\text{T}\left[\bm{\varXi}_t\odot\ln\bm{A}\right]\bm{I}
\end{align}$$
其中:
1、 $\displaystyle \eta_t[j]=p\big(z_t=j\mid \mathcal{D}_T^\bm{x}\big)$,也就说有 $\displaystyle \mathrm{E}_q\big[z_t[k]\big]=\eta_t[k]$,这根据分类分布不难理解。写成向量形式
$$\begin{align}
\mathrm{E}_q\big[\bm{z}_t\big]=\bm{\eta}_t
\end{align}$$
2、 $\displaystyle \xi_{t}[i,j]=p\big(z_{t-1}=i,z_t=j\mid \mathcal{D}_T^\bm{x}\big)$是隐变量两点边际概率。我们可以定义 $\displaystyle \bm{Z}_t=\bm{z}_{t-1}\bm{z}_t^\text{T}$,那么根据我们上面的推导有 $$\begin{align}
\mathrm{E}_q\big[\bm{Z}_t\big]=\sum_{\bm{Z}\in\{0,1\}^{K\times K}} \bm{Z}_t \mathrm{Cat} \big(\bm{Z}_t\mid \bm{\varXi}_t\big)=\bm{\varXi}_t
\end{align}$$也就说 $\displaystyle \mathrm{E}_q\big[z_{t-1}=i,z_t=j\big]=\xi_{t}[i,j]$。
2.3.2、求解 $\displaystyle \bm{\pi}$、 $\displaystyle \bm{A}$
显然若要求解参数 $\displaystyle \bm{\theta}=\{\bm{\pi},\bm{A},\bm{\rho}\}$,就必须知道 $\displaystyle \bm{\eta}_t,\bm{\varXi}_t$。这在之后的前向先后算法中我们已经求出,也就是 E 步。现在推导 $\displaystyle \textit{EM}$算法的 M 步。有:
$$\begin{align}
\exists \,\theta_{end}\to\max\ell \big(\mathcal{D}^\bm{x}\mid \theta\big)\iff\max \mathrm{E}_{q}\big[\ell\big(\mathcal{D}^+\mid \theta\big)\big]
\end{align}$$记$$\begin{align}
\mathrm{E}_{\mathcal{D}_T^+}=\mathrm{E}_{q}\big[\ln p\big(\mathcal{D}_T^+\mid \theta\big)\big]=\bm{\eta}_1^\text{T}\ln\bm{\pi}+\sum_{t=1}^T\bm{\eta}_t^\text{T}\ln \bm{\rho}_t+\sum_{t=2}^T\bm{I}^\text{T}\left[\bm{\varXi}_t\odot\ln\bm{A}\right]\bm{I}
\end{align}$$忽略 $\displaystyle p \big(\bm{x}_t\mid \varphi_k\big)$的严格定义 。先求解 $\displaystyle \bm{\pi}$、 $\displaystyle \bm{A}$。我们有:
$$\begin{align}
\mathrm{E}_{\mathcal{D}_T^+}
\propto \bm{\eta}_1^\text{T}\ln\bm{\pi}+\lambda\big[\bm{I}^\text{T}\bm{\pi}-1\big]
\end{align}$$得:$$\begin{align}
\begin{cases}
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \bm{\pi}}&\displaystyle=\frac{\bm{\eta}_1}{\bm{\pi}}+\lambda \bm{I}=\bm{0}\\
\\
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \lambda}&=\bm{I}^\text{T}\bm{\pi}-1=0
\end{cases}
\end{align}$$
易得:$$\begin{align}
\hat{\bm{\pi}}=\frac{\bm{\eta}_1}{\bm{I}^\text{T}\bm{\eta}_1}
\end{align}$$
考虑 $ \bm{A}$有:$$\begin{align}
\mathrm{E}_{\mathcal{D}_T^+}
\propto \sum_{t=2}^T\bm{I}^\text{T}\left[\bm{\varXi}_t\odot\ln\bm{A}\right]\bm{I}+\big[\bm{A}\bm{I}-\bm{I}\big]^\text{T}\bm{\delta}
\end{align}$$有:$$\begin{align}
\begin{cases}
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \bm{A}}&\displaystyle= \frac{\sum_{t=2}^T{\bm{I}\bm{I}}^\text{T}\odot \bm{\varXi}_t}{\displaystyle\bm{A}}+\bm{I}^\text{T}\bm{\delta}=\bm{0}\\
\\
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \bm{\delta}}&=\bm{A}\bm{I}-\bm{I}=\bm{0}
\end{cases}
\end{align}$$得:$$\begin{align}
\hat{\bm{A}}=\frac{\sum_{t=2}^T\bm{\varXi}_t}{\sum_{t=2}^T\bm{\varXi}_t \bm{I}}=\sum_{t=2}^\text{T} \frac{\bm{\varXi}_t}{\bm{\varXi}_t \bm{I}}
\end{align}$$
2.3.3、求解观测变量条件概率参数
考虑 $\displaystyle \bm{x}_t$服从分类分布,有条件密度:
$$\begin{align}
\rho_t[k]=p \big(\bm{x}_t\mid \varphi_k\big)=\mathrm{Cat}\big(\bm{x}_t\mid \bm{\mu}_k\big)=\prod_{c=1}^C\mu_{kc}^{x_t[c]}
\end{align}$$同时我们定义 $\displaystyle \bm{U}=[\mu_{ck}]_{K\times C}$,有:
$$\begin{align}
\mathrm{E}_{\mathcal{D}_T^+}
&\propto\sum_{t=1}^T\bm{\eta}_t^\text{T}\ln \bm{\rho}_t+\big[\bm{U}\bm{I}-\bm{I}\big]^\text{T}\bm{\kappa}
=\sum_{t=1}^T\sum_{k=1}^K\eta_t[k]\ln\bigg[\prod_{c=1}^C\mu_{kc}^{x_t[c]}\bigg]+\big[\bm{U}\bm{I}-\bm{I}\big]^\text{T}\bm{\kappa}\\
&=\sum_{t=1}^T\sum_{k=1}^K\eta_t[k] \cdot\bm{x}_t ^\text{T}\ln \bm{\mu}_k+\big[\bm{U}\bm{I}-\bm{I}\big]^\text{T}\bm{\kappa}\\
&=\sum_{t=1}^T \bm{\eta}_t^\text{T}\cdot\ln [\bm{U}]\cdot\bm{x}_t+\big[\bm{U}\bm{I}-\bm{I}\big]^\text{T}\bm{\kappa}
\end{align}$$ 求极值有:
$$\begin{align}
\begin{cases}
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \bm{U}}&\displaystyle= \frac{\sum_{t=1}^T\bm{\eta}_t \bm{x}_t ^\text{T}}{\bm{U}}+\bm{I}^\text{T}\bm{\kappa}=\bm{0}\\
\displaystyle\frac{\partial \mathrm{E}_{\mathcal{D}_T^+}}{\partial \bm{\kappa}}&=\bm{U}\bm{I}-\bm{I}=\bm{0}
\end{cases}
\end{align}$$可得
$$\begin{align}
\hat{\bm{U}}=\sum_{t=1}^T \frac{\bm{\eta}_t \bm{x}_t ^\text{T}}{\bm{\eta}_t \bm{x}_t ^\text{T} \bm{I}}
\end{align}$$
2.4、维特比算法
2.4.1、问题描述
定义隐变量数据集 $\displaystyle \mathcal{D}_T^z$,观测变量数据集 $\displaystyle \mathcal{D}_T^\bm{x}$,完全数据集 $\displaystyle \mathcal{D}^+_T$。维特比算法要解决的是求隐变量最可能状态序列。可以理解为:已知观测变量数据集,推断隐变量数据集:
$$\begin{align}
\hat{\mathcal{D}}_T^\bm{z}=\mathop{\mathrm{argmax}}_{\mathcal{D}_T^\bm{z}}\,p \big(\mathcal{D}_T^\bm{z}\mid\mathcal{D}_T^\bm{x}\big)
\end{align}$$注意到:
$$\begin{align}
p \big(\mathcal{D}_{t}^z\mid \mathcal{D}_t^\bm{x}\big)=p \big(\mathcal{D}_t^\bm{x},\mathcal{D}_{t}^z \big)\big/p \big(\mathcal{D}_t^\bm{x}\big)\propto p \big(\mathcal{D}_t^\bm{x},\mathcal{D}_{t}^z \big)
\end{align}$$相差一个常数 $ p \big(\mathcal{D}_t^\bm{x}\big)$,通过直接优化完全数据集会简化问题。我们选择最大化下式:
$$\begin{align}
\max_{\mathcal{D}_t^z} p\big(\mathcal{D}_t^\bm{x},\mathcal{D}_t^z\big)
=\max_{\mathcal{D}_t^z}\left[ p\big(z_1\big)p\big(\bm{x}_1\mid z_1\big)\bigg[\prod_{\tau=2}^tp\big(z_\tau\mid z_{\tau-1}\big)p\big(\bm{x}_\tau\mid z_\tau\big)\bigg]\right]\\
\end{align}$$其中完全数据集的概率 $\displaystyle \pi[i_1]\rho_1[i_1]\cdot\prod_{t=2}^T \bigg[A_t[i_{t-1},i_{t}]\cdot \rho_t[i_t]\bigg]$,写成对数形式有:
$$\begin{align}
\ln\pi[i_1]+\ln\rho_1[i_1]+\sum_{t=2}^T \bigg[\ln A_t[i_{t-1},i_{t}]+\ln \rho_t[i_t]\bigg]
\end{align}$$这个形式有利于我们着手分析。
2.4.2、前向计算
我们可以拆分隐变量数据集 $ \mathcal{D}_t^z=\mathcal{D}_{t-1}^z\cup \{z_t\}$,拆分的关键直觉是时刻 $ t$的最可能路径必须有是由时刻 $ t-1$的最可能路径组成。问题变为
$$\begin{align}
\max_{\mathcal{D}_t^z} p\big(\mathcal{D}_t^\bm{x},\mathcal{D}_t^z\big)
=\max_{z_t}\max_{\mathcal{D}_{t-1}^z} p \big(\mathcal{D}_{t-1}^z,z_t, \mathcal{D}_t^\bm{x}\big)
\end{align}$$追寻这一关键思想,下面来具体化:我们假设 $ t$时刻的状态为 $ i_t$,进而定义路径$ \mathcal{D}_t^z=\mathcal{D}_{t-1}^z\cup \{z_t=i_t\}$的最大概率(权重):
$$\begin{align}
\delta_t[i_t]=\max_{\mathcal{D}_{t-1}^z} p \big(\mathcal{D}_{t-1}^z,z_t=i_t, \mathcal{D}_t^\bm{x}\big)
\end{align}$$为了充分利用隐马尔可夫模型的条件独立性质和动态规划思想,假设 $ t-1$的状态为 $ i_{t-1}$。继续拆分数据集于是有:
$$\begin{align}
\delta_{t}[i_t]
&=\max_{\mathcal{D}_{t-1}^z} p \big(\mathcal{D}_{t-1}^z,z_t=i_t, \mathcal{D}_t^\bm{x}\big)\\
&=\max_{\mathcal{D}_{t-2}^z,z_{t-1}=i_{t-1}}\left[ p\big(z_1\big)p\big(\bm{x}_1\mid z_1\big)\bigg[\prod_{\tau=2}^tp\big(z_\tau\mid z_{\tau-1}\big)p\big(\bm{x}_\tau\mid z_\tau\big)\bigg]\right]\\
&=\max_{i_{t-1}}\bigg[p\big(z_t=i_t\mid z_{t-1}=i_{t-1}\big)p\big(\bm{x}_t\mid z_t=i_t\big)\max_{\mathcal{D}_{t-2}^z} p \big(\mathcal{D}_{t-2}^\bm{x},\mathcal{D}_{t-1}^z,z_{t-1}=i_{t-1}\big)\bigg]\\
&=\max_{i_{t-1}} \delta_{t-1}[i_{t-1}]A[i_{t-1},i_t]\rho_t[i_t]\\
\end{align}$$
也就是说:时刻 $ t$行至状态 $ i_t$的最可能路径必须有是由时刻 $ t-1$ 行至其他状态 $ i_{t-1}$的最可能路径组成。
$$\begin{align}
\delta_{t}[i_t]=\max_{i_{t-1}}\delta_{t-1}[i_{t-1}]A[i_{t-1},i_t] \rho_t[i_t]
\end{align}$$
写成矩阵形式固定 $\displaystyle i_t$,令$\displaystyle a[i_{t-1}]=A[i_{t-1},i_t]$则有
$$\begin{align}
\delta_t[i_t],\widehat{i}_{t-1}[z_t=i_t]
&=\max[\bm{\delta}_{t-1}\odot\bm{a}_{t-1}]\rho_t[i_t]\\
\bm{\delta}_t,\widehat{\bm{i}}_{t-1}
&=\big[\mathop{\mathrm{colmax}}[\bm{\delta}_{t-1}\odot\bm{A}]^\text{T}\odot\bm{\rho}_t
\end{align}$$
加上维度应该更容易理解
$$\begin{align}
\bm{\delta}_t,\widehat{\bm{i}}_{t-1}
&=\big[\underbrace{\mathop{\mathop{\mathrm{colmax}}[\underbrace{\mathop{\bm{\delta}_{t-1}}}_{1\times C}\odot\underbrace{\mathop{\bm{A}}}_{C \times C}}}_{C\times 1}\big]^\text{T}\odot\underbrace{\mathop{\bm{\rho}_t}}_{1\times C}
\end{align}$$
定义初始状态 $ \delta_1[i_1]=\pi[i_1]\rho_1[i_1]$,同时我们注意到 $\displaystyle i_t$是可以任意的,递归计算我们得到一个网格图 trellis diagram。
$$\begin{align}
\Delta=\{\bm{\delta}_1,\cdots,\bm{\delta}_t,\cdots,\bm{\delta}_T\}
\end{align}$$
2.4.3、后向回溯
回到我们的问题:已知观测变量数据集,推断隐变量数据集。最大化联合概率问题变为
$$\begin{align}
\max_{\mathcal{D}_T^z} p\big(\mathcal{D}_T^\bm{x},\mathcal{D}_T^z\big)
=\max_{i_T}\max_{i_{T-1}}A[i_{T-1},i_t] \rho_T[i_T]\cdots\max_{i_1}\delta_1[i_1]A[i_{1},i_2] \rho_2[i_2]
\end{align}$$
为了解决这个问题,回顾动态规划思想:最优路径 $ \hat{\mathcal{D}}_{1:T}^z$的一部分 $ \hat{\mathcal{D}}_{t:T}^z$对于 $ t:T$的所有可能路径 $ \mathcal{D}_{t:T}^z$必然是最优。如果存在另外一条路径 $ \tilde{\mathcal{D}}_{t:T}^z$是最优的,那么会出现矛盾 $ \hat{\mathcal{D}}_{1:t}^z\cup \tilde{\mathcal{D}}_{t:T}^z\neq \hat{\mathcal{D}}_{1:T}^z $,所以 $ \hat{\mathcal{D}}_{t:T}^z$ 必须是最优的。根据这一思想,我们定义回溯操作 traceback : $ \omega_t[\cdot]$,来从后向前还原最优状态序列。
$$\begin{align}
\hat{z}_{t-1}=\omega_t[i_t]=\mathop{\mathrm{argmax}}_{i_{t-1}}\,\delta_{t-1}[i_{t-1}]A[i_{t-1},i_t] \rho_t[i_t]
\end{align}$$定义 $ T$时刻最优状态 $\displaystyle \hat{z}_{T}=\mathop{\mathrm{argmax}}_{i_T}\,\delta_T[i_T]$。应用回溯操作,得到最优路径:
$$\begin{align}
\hat{\mathcal{D}}_{T}^z=\{\hat{z}_{t-1}=\omega_t[\hat{z}_{t}]\}_{t=T}^1
\end{align}$$
为了解决数据下溢问题,我们可以取对数
$$\begin{align}
&\ln\delta_{t}[i_t]
=\max_{i_{t-1}}\big[\ln\delta_{t-1}[i_{t-1}]+\ln A[i_{t-1},i_t] +\ln\rho_t[i_t]\big]\\
&\hat{z}_{t-1}=\omega_t[i_t]=\mathop{\mathrm{argmax}}_{i_{t-1}}\,\big[\ln\delta_{t-1}[i_{t-1}]+\ln A[i_{t-1},i_t] +\ln\rho_t[i_t]\big]
\end{align}$$
算法:维特比算法
1 $\displaystyle \bm{\delta}_1=\bm{\pi}$
2 $\displaystyle \text{ for }\,t=2:T$
$\displaystyle
\quad\begin{array}{|lc}
\text{ for }\,i_{t}=1:C \\
\quad\begin{array}{|lc}
\displaystyle \text{Traceback_Data}=\big[\ln\delta_t[i_t],\omega_{t-1}[i_t]\big]=\big[\mathop{\mathrm{colmax}}[\ln\bm{\delta}_{t-1}+\ln\bm{A}\big]^\text{T}+\ln\bm{\rho}_t
\end{array}\\
\text{ end}\\
\end{array}
$
3 end
$\displaystyle [\ln\delta_T,\hat{z}_{T}]=\max_{i_T}\,\ln\bm{\delta}_T$
4 $\displaystyle \text{ for }\,t=T:2$
$\displaystyle
\quad\begin{array}{|lc}
\hat{z}_{t-1}=\omega_{t}[\hat{z}_{t}]
\end{array}
$
5 end
6 $\displaystyle \hat{\bm{z}}$
三、总结
1、隐马尔可夫是一个古老的模型,开始我们回顾了一下它的基本问题
2、然后我们使用前向后向算法和维比特算法,解决了求值和求隐状态的问题。
3、中间我们使用 $\displaystyle EM$算法,解决了参数求解的问题。
4、人类可以通过一些精巧的设计,来获取超乎直观想象结果,当人类的思想开始集成,开始向深处,广处延伸时,上帝似乎很惊异。
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/9b154bbdc2a51d2ea34ec070684b5132/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Mar. 11, 2017). 《隐马尔可夫模型》[Blog post]. Retrieved from https://www.limoncc.com/post/9b154bbdc2a51d2ea34ec070684b5132 |
| @online{limoncc-9b154bbdc2a51d2ea34ec070684b5132, title={隐马尔可夫模型}, author={引线小白}, year={2017}, month={Mar}, date={11}, url={\url{https://www.limoncc.com/post/9b154bbdc2a51d2ea34ec070684b5132}}, } |