作者: 引线小白-本文永久链接:httpss://www.limoncc.com/post/cbc3dd8ffe60158f/
知识共享许可协议: 本博客采用署名-非商业-禁止演绎4.0国际许可证
一、引言
近日[2024-01-21]商汤科技与上海AI实验室联合香港中文大学、复旦大学,发布了新一代大语言模型书生·浦语2.0(InternLM2)。在一系列典型评测集上,InternLM2只用20B参数的中等规模即在整体表现上达到了与ChatGPT比肩的水平。而在AGIEval、 BigBench-Hard(BBH)、GSM8K、MATH等对推理能力有较高要求的评测上,InternLM2的表现甚至要优于ChatGPT。
更重要是InternLM2支持20万tokens的上下文,能够一次性接受并处理约30万汉字(约五六百页的文档)的输入内容,并准确提取关键信息,实现长文本中“大海捞针”。
像相比GML4d闭源。书生·浦语2.0可谓难能可贵。关键开源中支持30万字长文的模型。同比规模情况下,最强中文开源模型之一的一句评价不为过。
二、如何量化
使用LLaMA.cpp部署模型,最大的需求或者说动力就是能支持CPU部署。不需要使用GPU就能运行。虽然行内专业人士都还是倾向使用GPU部署。笔者一次和某土豪风格老板交流,人家也说没有GPU怎么玩大模型。而实际上并非如此,对于个人用户、中小企业而言,使用CPU部署(推理)大模型是成本最佳方案。大大扩充和降低大模型应用边界和门槛。这也笔者为何撰写本文的原因。
2.1、书生·浦语2.0实现CPU部署障碍
InternLM2社区的同学poemsmile做了总结
1、目前看起来和llama.cpp不适配的地方主要是两个,一个是llama.cpp不支持dynamic ntk,但这个几乎已经是用得最广泛的外推方法之一了,并且我们只在这个上面验证了可以外推到200k;另一个是tokenizer两边是不同的,但这个也是为了更好的tokenizer压缩率和加入中文之类的。
2、至于internlm和llama的差异,正如之前讨论的那样,我们希望把wq\wk\wv这个矩阵合并起来提高训练效率,对于我们这个可以节省超过5%的成本,对于预训练来说是相当可观的一笔了。
3、因为llama的这个格式,token中不能有control code,这些control code会导致https://github.com/ggerganov/llama.cpp/blob/77bc1bbd05f0c31cb45773eb5eb59b9ff2b07e1b/llama.cpp#L3005 这里无法通过assert(因为control code的长度为0了);目前还没有彻底解决的方案(我们正在研究尝试给llama.cpp提交pr看看能不能修复),当前只能通过一些方法绕开。目前的临时方案是使用一些emoji符号强行占住了这些会报错的control code位置,由于这些control code一般不怎么使用,大部分情况下不会对推理有什么负面影响.
如果你对量化不感兴趣,只想直接使用请下载模型,看第三部分内容即可。
https://modelscope.cn/models/limoncc/internlm2-chat-7b-gguf
我已经将量化好的模型上传到了魔塔社区。
2.2、如何解决
2.2.1 第一步、与llama对齐
针对第二个问题,官方提供了一个转换脚步,和llama架构对齐
https://github.com/InternLM/InternLM/tree/main/tools
首先下载官方模型,然后下载这个脚本,准备一些必要环境,主要torch、transformers等一些包,自己看着安装
然后1
python convert2llama.py --src ./internlm2_path --tgt ./target/path
转换之后你会得到如下文件
1 | . |
2.2.2 第二步、与llama对齐
针对第三个问题,InternLM2社区的同学poemsmile提供了一个修复文件
夸克网盘分享了「internlm_tokenizer_llamacpp_fix.zip」
链接:https://pan.quark.cn/s/be6de3248d8f
提取码:ghpB
下载复制到转换目录,替换原来的文件即可。这个动作主要是替换了id=354的token。”🐉”: 354。这个token原来是\u0000,为了应景poemsmile同学把它换成了一条龙。搞AI的还是以萌为尊哈,毕竟huggingface还是叫抱抱脸🤗。
2.2.3 第三步、解决位置编码问题
最后解决第一个问题
转换后的config.json文件中有这样的配置1
2
3
4"rope_scaling": {
"factor": 2.0,
"type": "dynamic"
}
需要改为1
"rope_scaling": null
当然这也意味者对长度外推的能力有影响,目前没有测试,目前解决这个问题需要等llama.cpp官方修复。
2.2.4 第四步、量化模型
解决了前面的问题就是生成gguf格式的模型了,如果你对gguf是什么感兴趣,可以参考我这篇文章揭开gguf神秘面纱——大模型CPU部署系列02
下载llama.cpp的代码并编译,这个非常简单,具体请参考官网
1 | 转换 |
三、如何使用
3.2、对于个人用户
你可以使用llama.cpp的main命令行工具,或者LM studio这类UI。需要特别注意的是chat format的格式问题。范例如下:
对于llama.cpp的main命令行1
2
3 ./main -m ../models/internlm/target/ggml-model-Q4_K_M.gguf \
--temp 0.2 --top-p 0.9 --top-k 5 --repeat_penalty 1.1 -ngl -1 \
--color -ins -r [UNUSED_TOKEN_145]
[UNUSED_TOKEN_145]是对话角色的停止token. 其实可以修改原始文件改为大多数人使用的,目前官方没有修改哈。大家注意一个stop token的设置即可:[““, ‘<|im_end|>’,’[UNUSED_TOKEN_145]’],目前是这三个
对于LM studio, 你需要新建一个预置文件internlm2
1 | { |
然后设置如下token
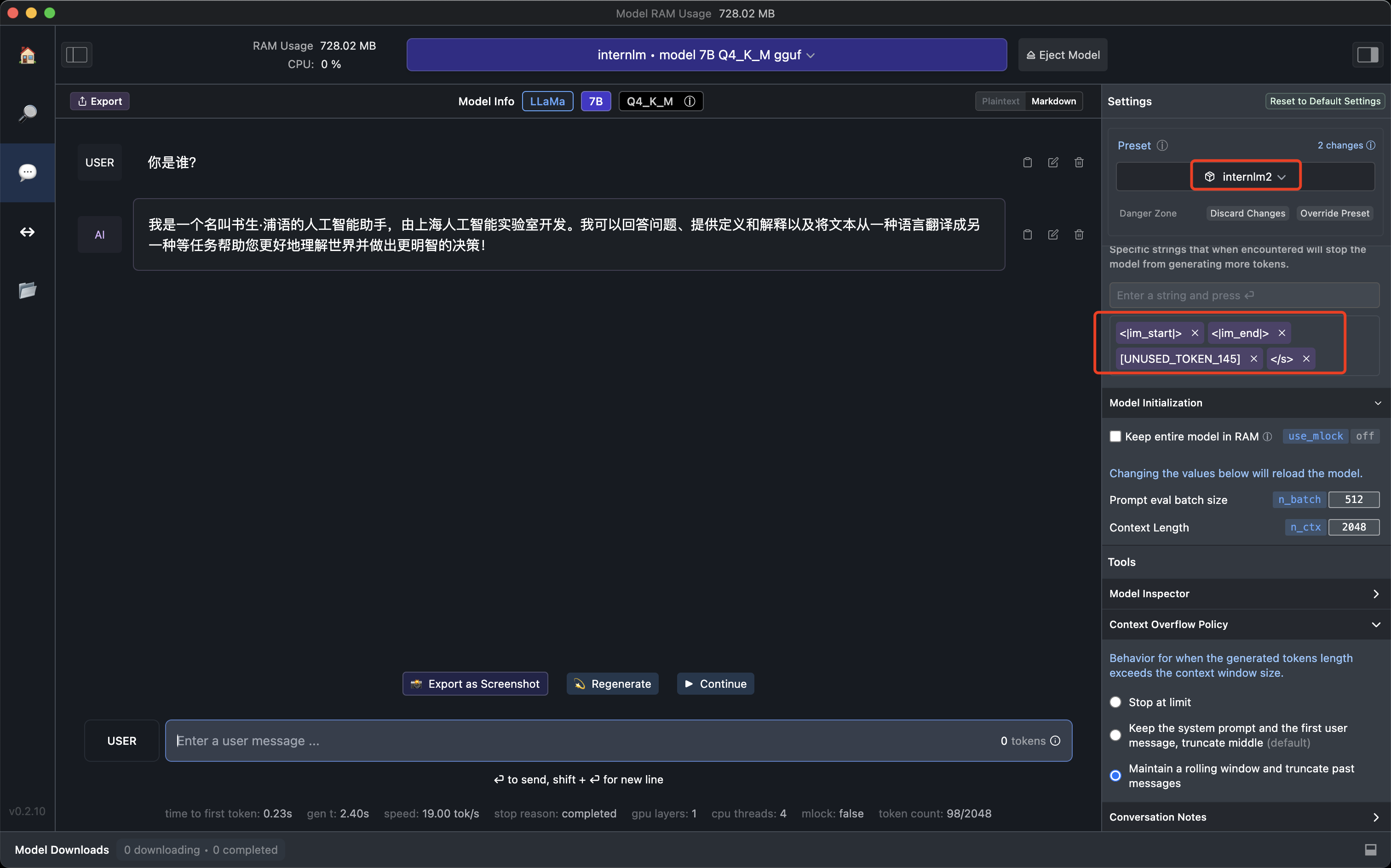
当然如果你对chat format不熟悉,可以参考我的这篇文章
不得不说的Chat Format(聊天格式)——大模型CPU部署系列03
3.1、对于企业和开发者用户
我这里提供llama-cpp-python的部署方案,我们非常简单
1 | python -m llama_cpp.server \ |
然后使用openai的客户端调用模型即可
1 | from openai import OpenAI |
| 版权声明 |  |
| 由引线小白创作并维护的柠檬CC博客采用署名-非商业-禁止演绎4.0国际许可证。 本文首发于柠檬CC [ https://www.limoncc.com ] , 版权所有、侵权必究。 | |
| 本文永久链接 | httpss://www.limoncc.com/post/cbc3dd8ffe60158f/ |
| 如果您需要引用本文,请参考: |
| 引线小白. (Jan. 21, 2024). 《如何使用llama.cpp部署InternLM2——大模型CPU部署系列05》[Blog post]. Retrieved from https://www.limoncc.com/post/cbc3dd8ffe60158f |
| @online{limoncc-cbc3dd8ffe60158f, title={如何使用llama.cpp部署InternLM2——大模型CPU部署系列05}, author={引线小白}, year={2024}, month={Jan}, date={21}, url={\url{https://www.limoncc.com/post/cbc3dd8ffe60158f}}, } |